Escape the Cloud Tax – Post 1: “Why We Built EdgeMatrix: One Runtime to Rule Inference”
The cloud made AI accessible.
But it also made it expensive.
And slow.
And… inconvenient to control.
So we asked a harder question:
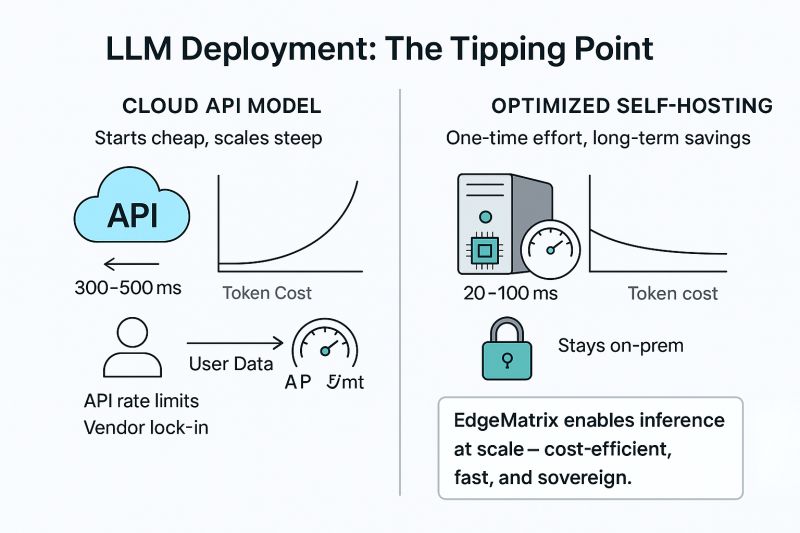
“Can we make inference fast, affordable, and fully sovereign – for any model, on any hardware?”
Meet EdgeMatrix – our answer to the growing gap between what GenAI needs and what cloud APIs offer.
It’s a high-performance inference engine that delivers:
✅ 3–6× acceleration on CPUs
✅ 20–60% throughput gains on GPUs
✅ Supports quantized & raw models (INT4 / INT8 / FP16)
✅ Deploys seamlessly across edge, on-prem, or hybrid clouds
And it works across architectures – LLaMA, Qwen, Phi, Mistral, and more.
EdgeMatrix isn’t just a trick for small models.
We tested it across real-world, production-scale workloads:
🧠 LLaMA: 3B, 8B, 70B
🧠 Qwen: 0.6B, 4B, 8B, 14B
🖥️ Across A100, L40S, RTX 4090, and CPU-only machines
Benchmark Highlights:
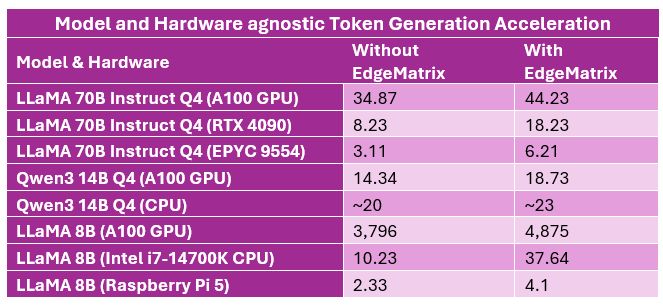
LLaMA 70B Instruct (Quantized Q4)
– A100 GPU: 34.87 → 44.23 tokens/sec
– RTX 4090: 8.23 → 18.23 tokens/sec
– CPU (EPYC 9554): 3.11 → 6.21 tokens/sec
Qwen3 14B Q4
– A100 GPU: 14.34 → 18.73 tokens/sec
– CPU: ~20 → ~23 tokens/sec
LLaMA 8B
– A100 GPU: 3,796 → 4,875 tokens/sec
– CPU (Intel i7-14700K): 10.23 → 37.64 tokens/sec
– Raspberry Pi 5: 2.33 → 4.10 tokens/sec
Even massive models like LLaMA-70B become deployable on-prem – at usable speed – when EdgeMatrix kicks in.
With EdgeMatrix we quantized (Q4) LLaMA 70B mode, the model was compressed from 150GB to ~39GB, unlocking edge & constrained-device inference.
Whether you’re building:
💬 Real-time enterprise copilots
🔍 RAG-backed search systems
📑 On-prem document/chat assistants
EdgeMatrix gives you performance that scales with your ambition – without scaling your cloud bill.