Escape the Cloud Tax – Post 2: “Cloud APIs vs Self-Hosting – Rethinking LLM Deployment at Scale”
Most teams begin their GenAI journey using cloud-based LLM APIs – and for good reason.
– They’re convenient
– Pay-as-you-go feels cost-efficient
– Time-to-deploy is near instant
But as usage grows, many start to feel the friction:
🧾 Token costs balloon
⏱️ Inference latency becomes a bottleneck
🔐 Data privacy and control go out the window
📉 And… rate limits hit at the worst time
Here’s the truth most teams realize late:
✅ Self-hosting doesn’t have to mean slower, costlier, or more complex.
With the right runtime layer, it can be faster, cheaper, and sovereign.
That’s exactly what we’ve built with EdgeMatrix at SandLogic:
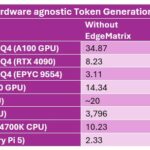
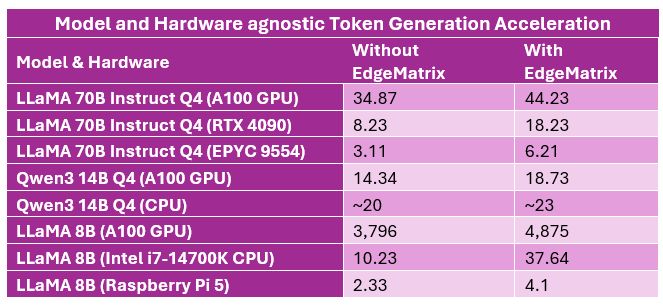
– Up to 6.5× faster inference on commodity CPUs
– Supports GPUs like H100, A100, L40S, even Raspberry Pi 5
– On-prem & edge deployment ready
– Fully data-sovereign, no vendor lock-in
We call it Intelligent Inference at the Edge.
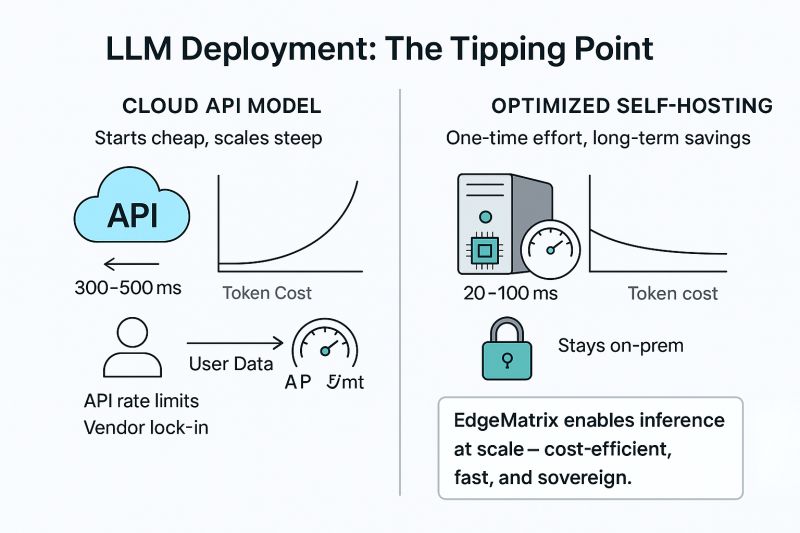
I’ve attached a quick visual below showing where the tipping point lies between cloud APIs and intelligent self-hosting.
In the next post, I’ll share our real-world benchmarks vs Groq, Together, and others. Stay tuned.
What’s been your experience with scaling LLM workloads – are you still in the API phase or already exploring self-hosted options?