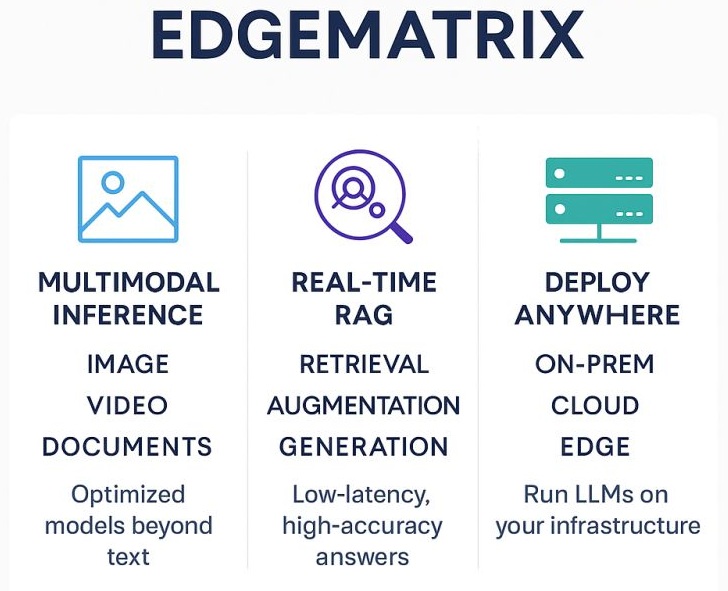
Escape the Cloud Tax – Post 7: “What’s Next for EdgeMatrix: Beyond Text, Toward Real-Time Intelligence”
Over the last few posts, we’ve broken down why inference efficiency is non-negotiable when deploying GenAI at scale:📉 Lower token
0 Comments
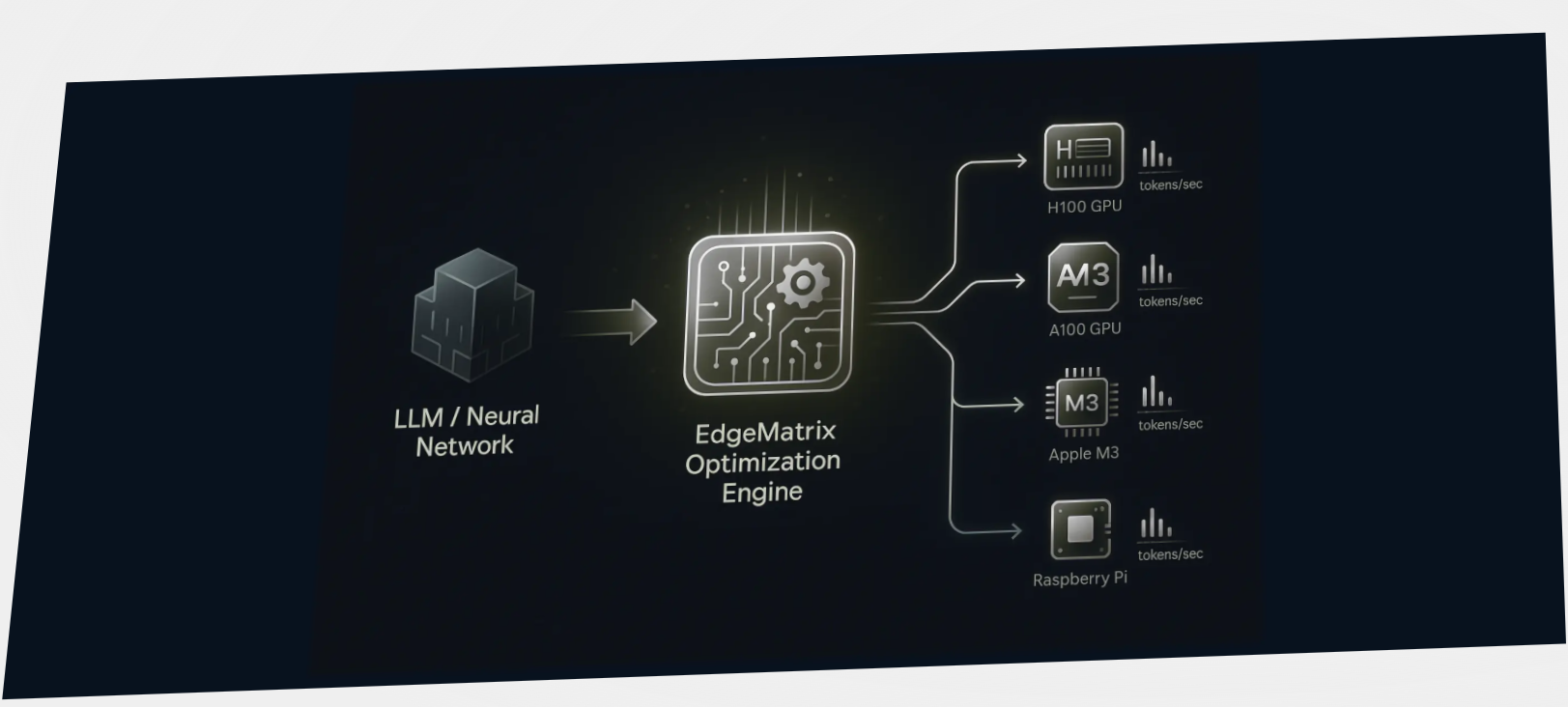
Escape the Cloud Tax – Post 6: “The True Cost of Tokens – LLM Inference ROI Unmasked”
Running GenAI at scale?Here’s the truth no API provider advertises: Tokens are your new cloud tax.And if you're consuming millions
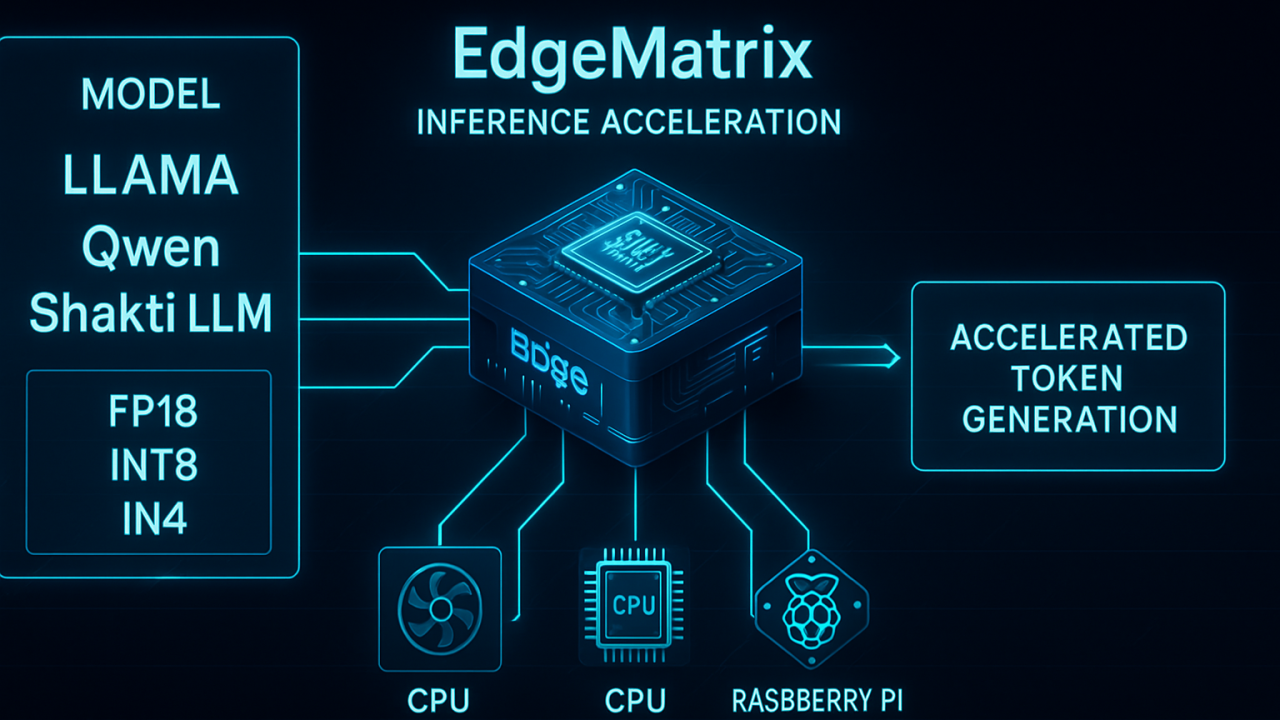
Escape the Cloud Tax – Post 5: “Serve Faster. Spend Smarter. Scale Better.”
As GenAI applications move from prototype to production, inference demands are exploding — across models, hardware, and environments. But most runtime
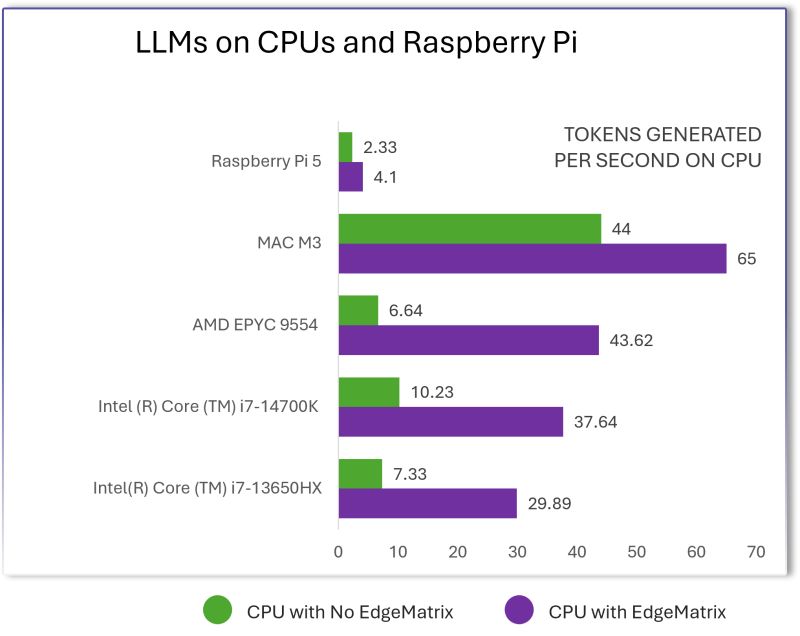
Escape the Cloud Tax – Post 4: “LLMs on CPUs, Raspberry Pi & Beyond – EdgeMatrix at the Edge”
Most people assume that to run LLMs well, you need an H100 or expensive cloud GPUs.We decided to challenge that
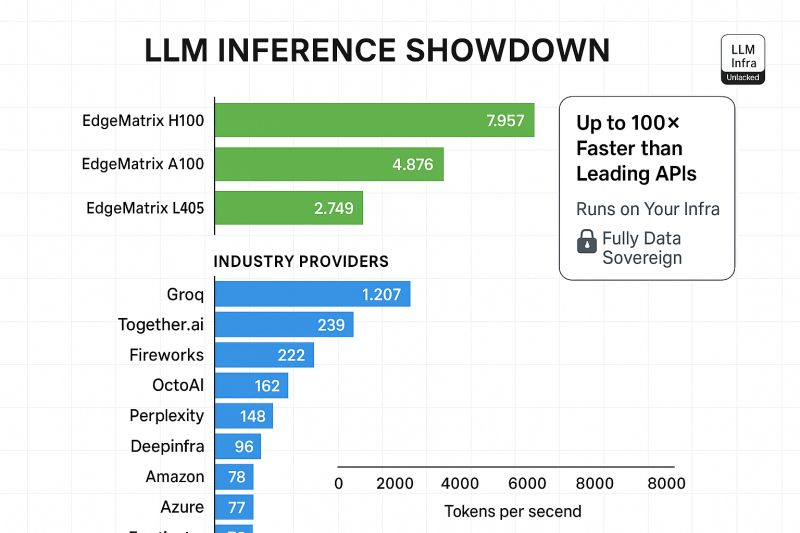
Escape the Cloud Tax – Post 3: “LLM Inference Showdown: EdgeMatrix vs the Rest”
LLMs aren’t just about parameter counts anymore.When deploying LLMs at scale, performance isn’t theoretical - it’s measured in tokens per