Escape the Cloud Tax – Post 3: “LLM Inference Showdown: EdgeMatrix vs the Rest”
LLMs aren’t just about parameter counts anymore.
When deploying LLMs at scale, performance isn’t theoretical – it’s measured in tokens per second.
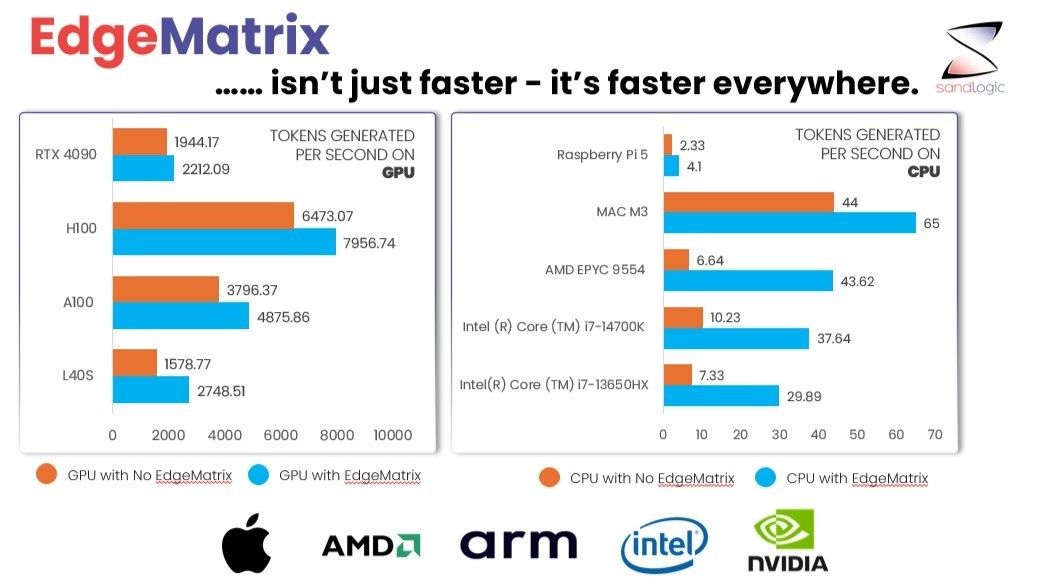
We ran LLaMA 3 8B (1000-token input) through a benchmarking gauntlet.
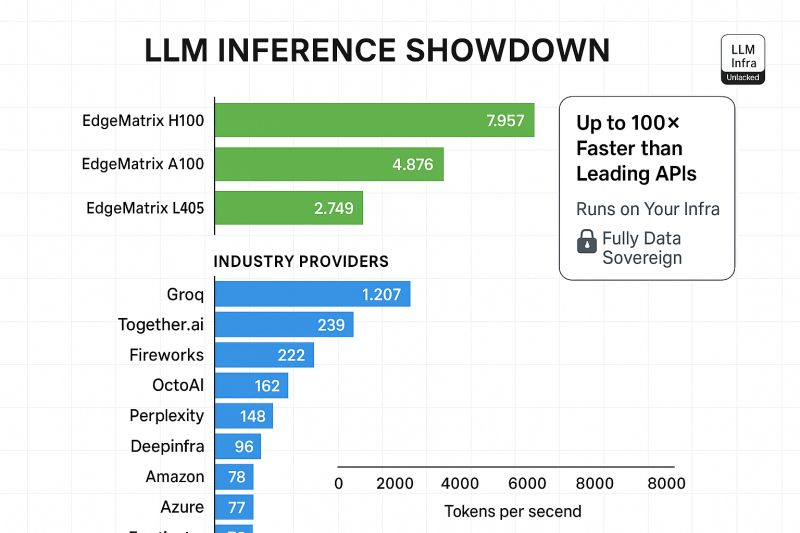
EdgeMatrix outperformed every major provider – including Groq, Together.ai, OctoAI, and more.
Here’s what we saw:
✅ EdgeMatrix on H100: near 8,000 tokens/sec
✅ A100: nearly 5,000
✅ L40S: over 2,700
Compare that with top cloud APIs – many hovering under 300 tokens/sec.
No tricks. No shortcuts. Just optimized runtime that makes every FLOP count.
That’s up to 100× faster inference compared to some cloud APIs – with full control over infra, cost, and latency.
No rate limits. No API surprises. No external data exposure – Just blazing-fast token generation, on your terms.
Want to try these benchmarks on your infra?
We’re opening up EdgeMatrix pilots for early access.
Until now, we’ve focused on why EdgeMatrix delivers speed and savings – in our next post, will talk about how it beats top-tier open-source runtimes like in real-world benchmarks.