Escape the Cloud Tax – Post 5: “Serve Faster. Spend Smarter. Scale Better.”
As GenAI applications move from prototype to production, inference demands are exploding — across models, hardware, and environments.
But most runtime engines were built with narrow assumptions:
- GPU-first workloads
- Fixed memory budgets
- Limited support for quantization
- Little flexibility for edge or hybrid deployment
- We built EdgeMatrix to break those assumptions.
We’ve always believed that the true scale of GenAI adoption in enterprises will only be possible when these models can run efficiently on widely accessible hardware. That’s why we built EdgeMatrix — a high-performance inference engine that gives teams:
- Up to 70% higher throughput across models and hardware
- Native support for INT4, INT8, and FP16 models
- Acceleration on CPUs and GPUs alike
- Deployment freedom — edge, on-prem, or hybrid cloud
Why We Benchmarked EdgeMatrix Across Models, Hardware, and Runtime Engines?
Most GenAI inference stacks look fast… until you scale across real-world constraints:
- Quantized models
- Heavy workloads
- Mixed hardware across edge and data centers
EdgeMatrix is our answer — a high-performance runtime engine optimized for every part of the LLM deployment landscape.
To prove its performance, we ran head-to-head benchmarks across:
- Shakti 8B, LLaMA 8B, LLaMA3 8B, and Qwen 8B
- Multiple quantization formats: INT4, INT8, FP16
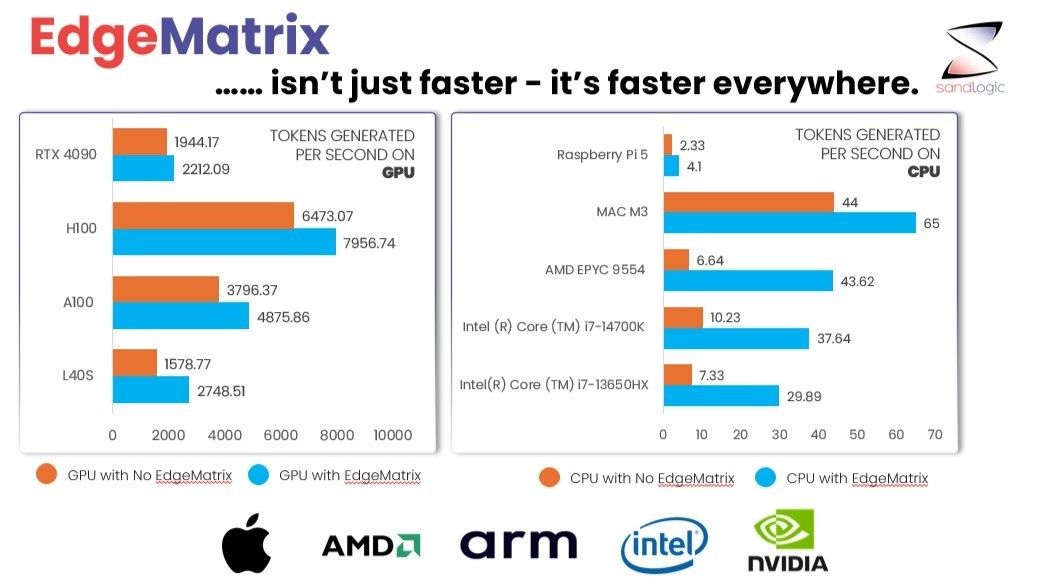
- Diverse hardware: A100, RTX 4090, Intel i7, AMD EPYC
And we compared against top-tier runtimes — including VLLM and TensorRT-LLM.
Whether you’re deploying LLMs on powerful GPUs or tiny edge boxes, EdgeMatrix consistently outperforms — often by 30% to 80%.



Qwen3 Meets EdgeMatrix: Unleashing Near 2× Speed Gains on Everyday Hardware
As a deeper look into the model-level performance dynamics, we benchmarked the Qwen3 series (0.6B to 8B) across various deployment scenarios — from enterprise GPUs like A100 to consumer-grade Intel CPUs. The results reaffirmed EdgeMatrix’s strength: consistent, architecture-agnostic acceleration. Whether it’s INT4 on a CPU or FP16 on a high-end GPU, EdgeMatrix delivered up to 93% faster inference on CPUs and up to 27% gains on GPUs. This granularity shows how teams can extract real-world, scalable performance — even on commodity hardware — with models like Qwen, without vendor lock-ins or spiraling API costs.

This isn’t about being better in labs. It’s about unlocking real-world GenAI at scale — without vendor lock-in, GPU dependency, or ballooning inference costs.
By unlocking near-GPU-level performance on widely accessible hardware, EdgeMatrix redefines the economics and scalability of GenAI deployment. Whether you’re an enterprise optimizing for cost, a developer building on the edge, or a startup constrained by cloud expenses — this level of acceleration puts real-time LLM capabilities within reach.