Escape the Cloud Tax – Post 4: “LLMs on CPUs, Raspberry Pi & Beyond – EdgeMatrix at the Edge”
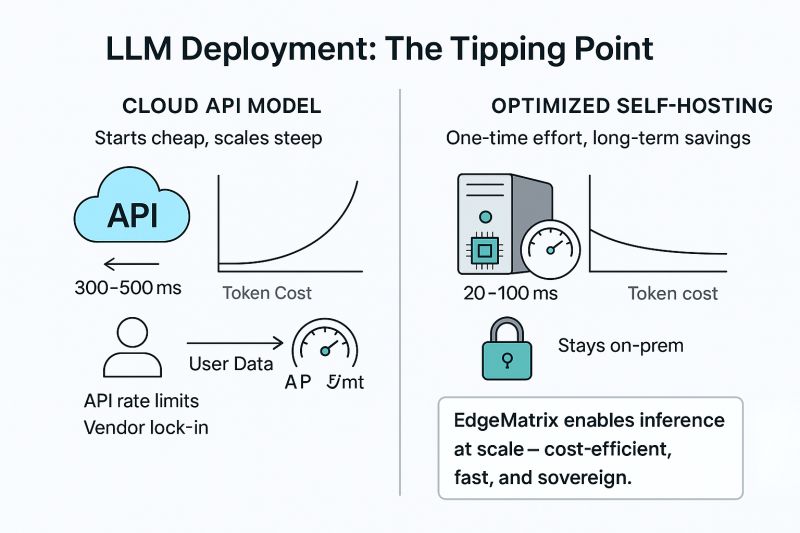
Most people assume that to run LLMs well, you need an H100 or expensive cloud GPUs.
We decided to challenge that assumption.
What if you could get fast, scalable inference on:
🖥️ Commodity CPUs?
🧠 Consumer-grade Apple silicon?
🔌 Even a Raspberry Pi 5?
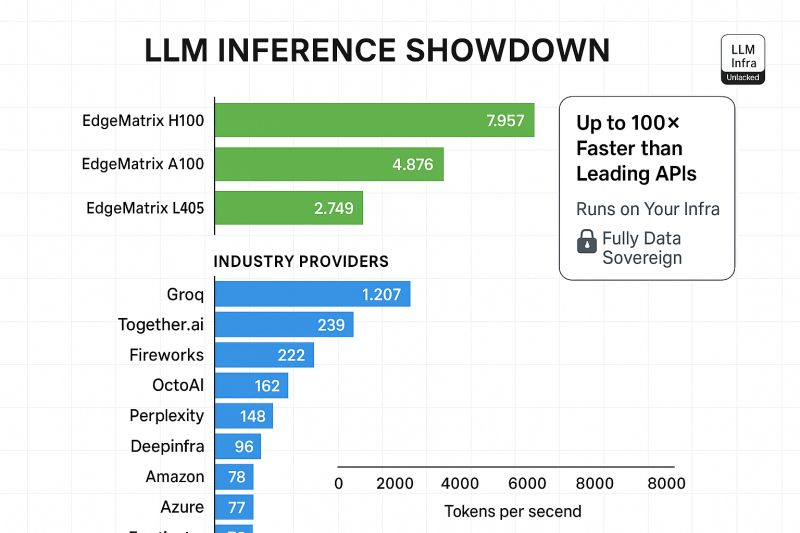
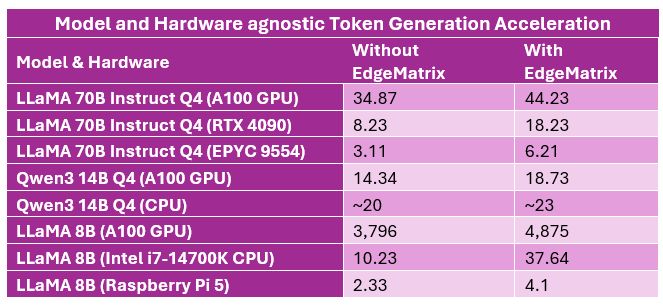
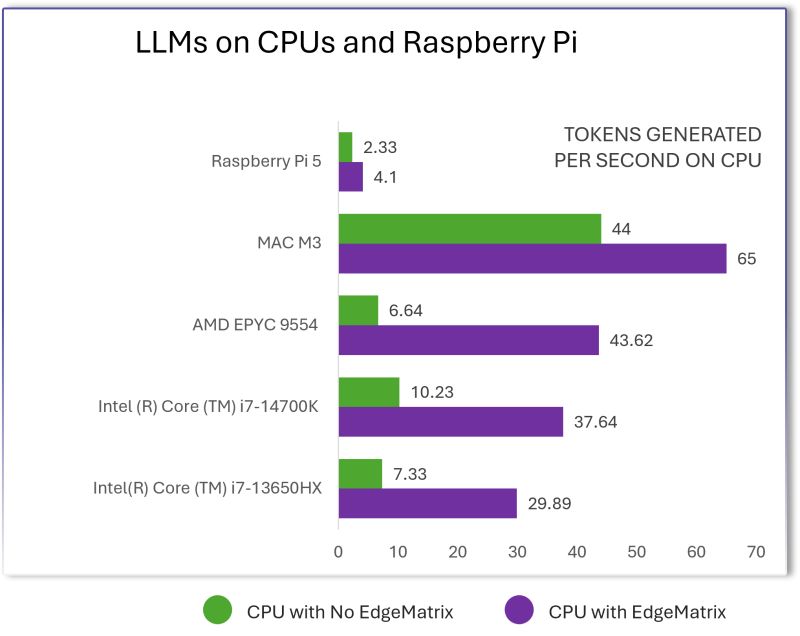
We ran the LLaMA 8B model across a range of non-GPU devices — using EdgeMatrix to optimize every bit of performance.
Here’s what we saw:
🟣 Intel Core i7-14700K → From 10.2 to 37.6 tokens/sec — 🔼 3.7× boost
🟣 AMD EPYC 9554 → From 6.6 to 43.6 tokens/sec — 🔼 6.5× boost
🟣 Mac M3 → From 44 to 65 tokens/sec
🟣 Raspberry Pi 5 → From 2.3 to 4.1 tokens/sec
Yes — even the Pi.
EdgeMatrix enables LLM inference on CPUs at the edge, with:
✅ Near real-time generation speeds
✅ 3×–6× acceleration on average
✅ Zero dependence on cloud APIs or external GPUs
This is the future of GenAI:
From cloud-only to edge-ready. From GPU-bound to CPU-optimized.
In the next post, we’ll walk through cost economics of inference using EdgeMatrix vs public APIs – what it means for ROI when tokens scale into millions.