Escape the Cloud Tax – Post 6: “The True Cost of Tokens – LLM Inference ROI Unmasked”
Running GenAI at scale?
Here’s the truth no API provider advertises: Tokens are your new cloud tax.
And if you’re consuming millions per day, you’re footing a serious bill.
Let’s talk real numbers 👇
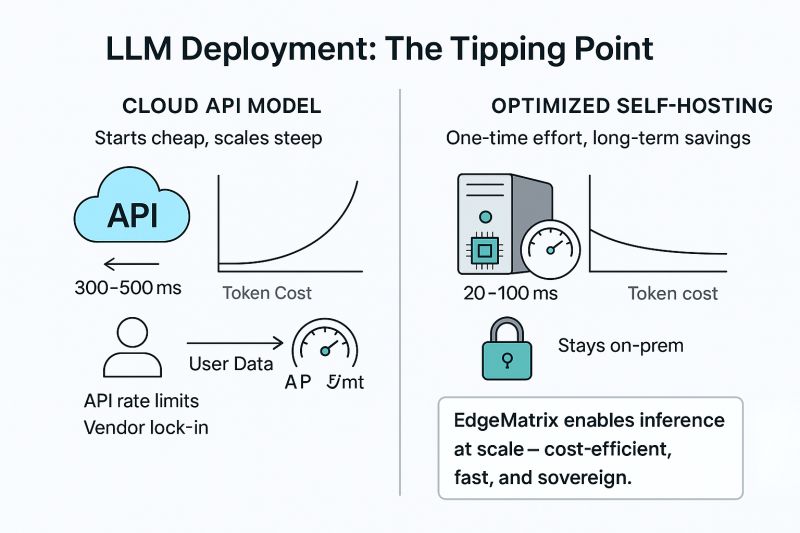
☁️ Public LLM APIs: Predictably Expensive
GPT-4 Turbo → ~$30 per 1M tokens
Claude Opus → ~$90+ per 1M tokens
5M tokens/day = $150 to $450/day
That’s $55K–$165K/year on inference alone
Now scale that across teams, agents, or 24/7 products – and it spirals.
🧠 EdgeMatrix: Rewriting the Economics of Inference
Deploying LLMs with EdgeMatrix on your infra means:
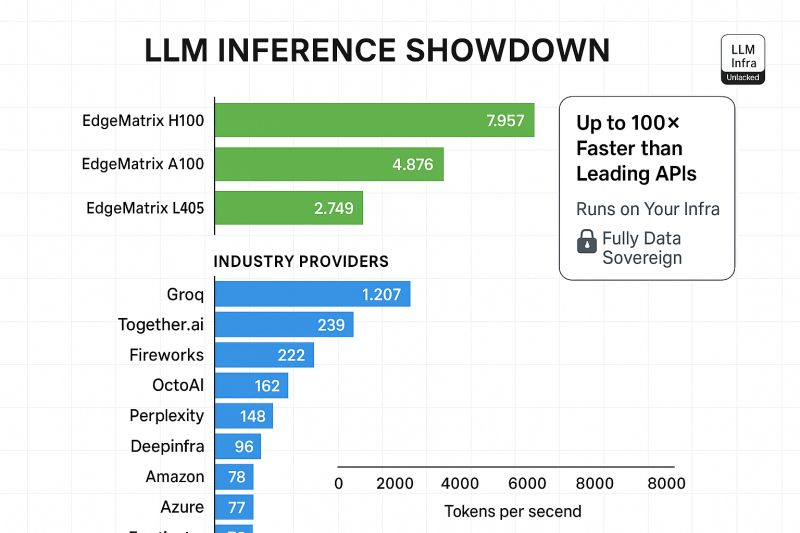
💰 30–60% lower cost/token on GPUs – across various models
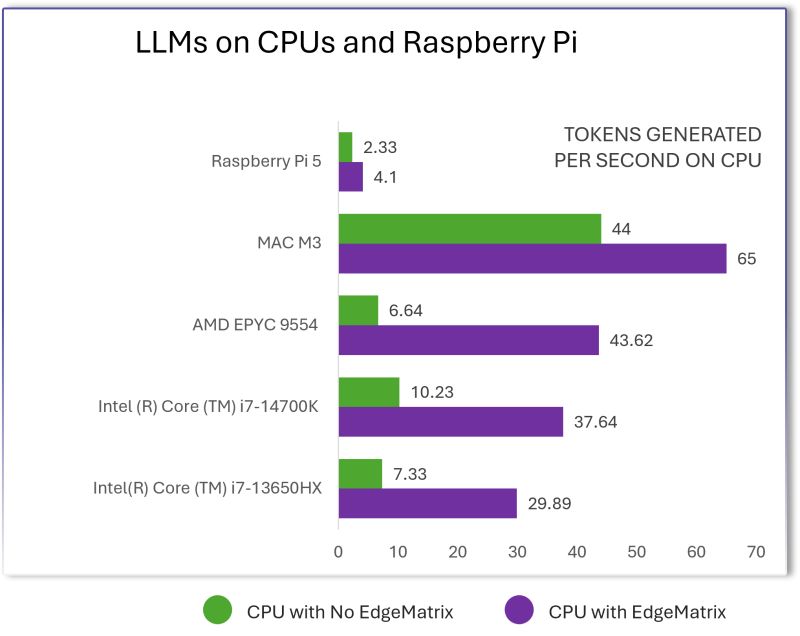
🧮 3–6× throughput on CPUs (no GPU needed) – across various models
📦 Supports quantized models (INT4, INT8)
💡 One-time infra cost → years of savings
🔐 Full data control and sovereignty
EdgeMatrix isn’t just faster. It’s designed for sustainable AI ops.
If you’re scaling to millions of tokens per day, the cloud tax compounds fast.
Escape it.
Run LLMs your way – faster, cheaper, and fully in control.