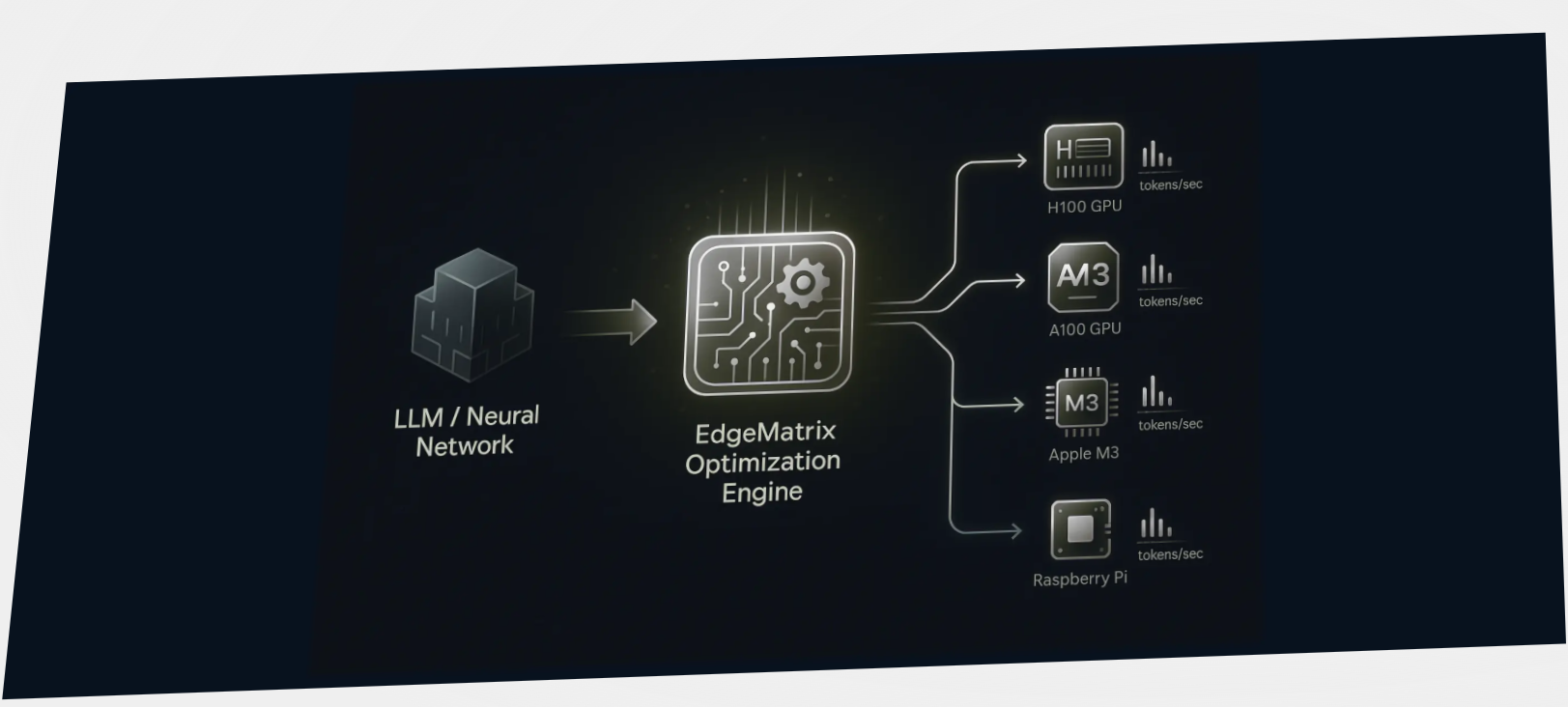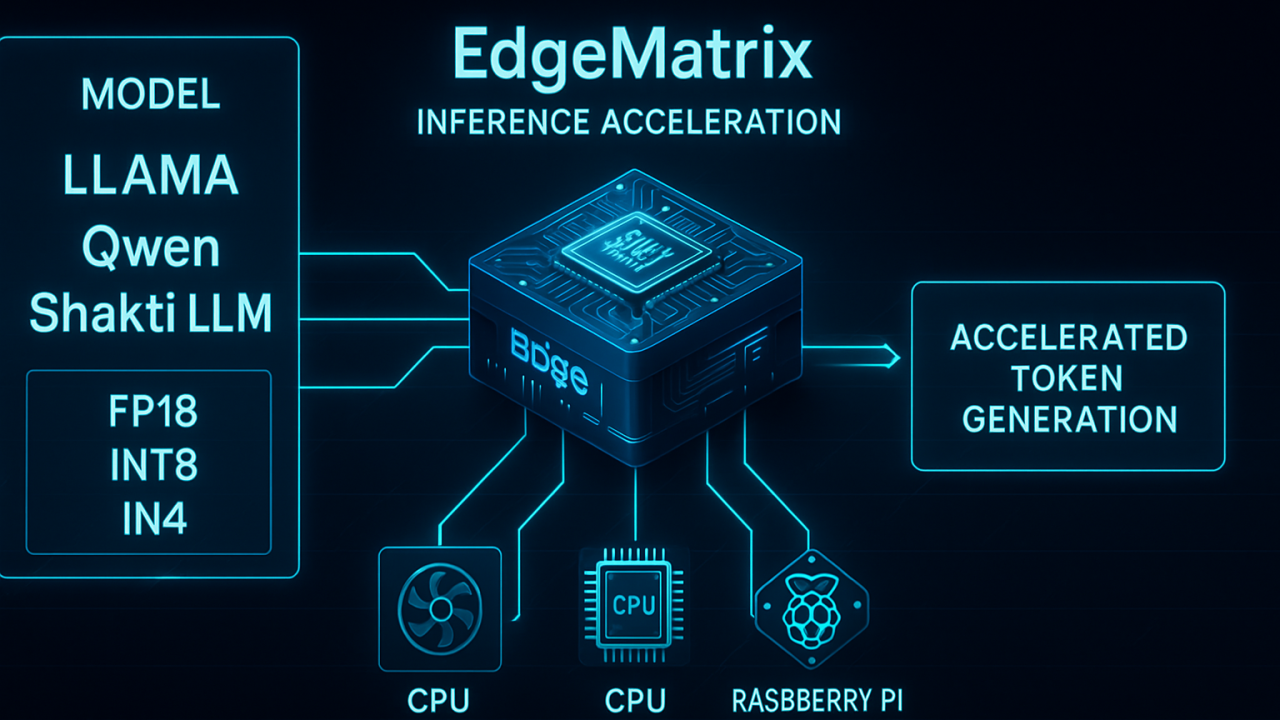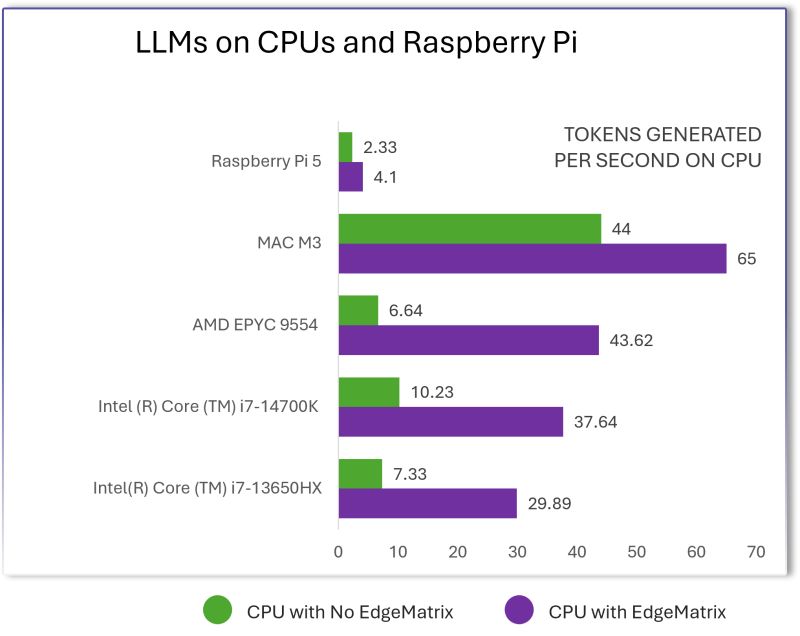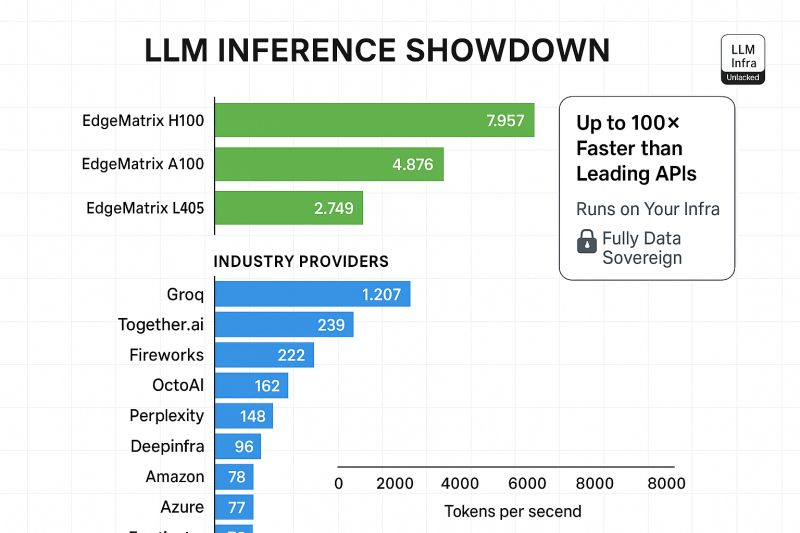
Escape the Cloud Tax – Post 7: “What’s Next for EdgeMatrix: Beyond Text, Toward Real-Time Intelligence”
Over the last few posts, we’ve broken down why inference efficiency is non-negotiable when deploying GenAI at scale:
📉 Lower token costs
⚡ Faster generation
🔒 Data sovereignty
💡 CPU + GPU flexibility
But EdgeMatrix isn’t just about speeding up LLMs.
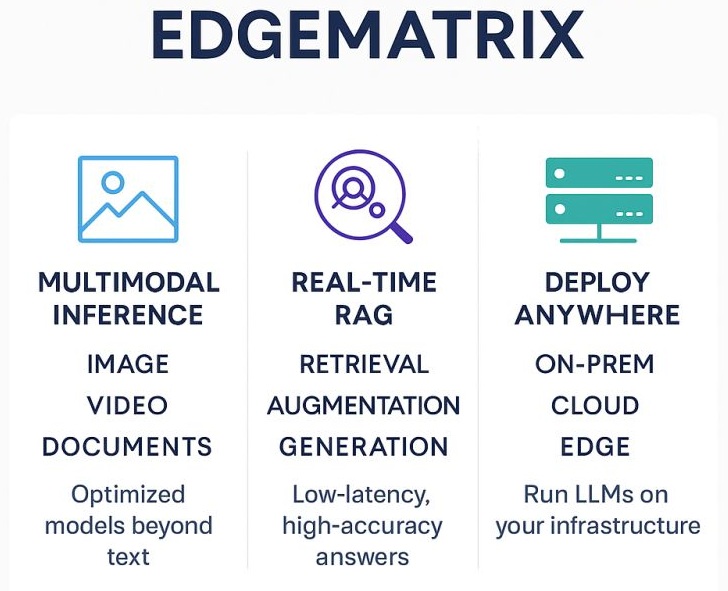
🧠 Here’s what’s coming next: 🎥 Multimodal Acceleration
EdgeMatrix will soon support optimized inference for image, chart, document, and video models – not just text.
Use cases like:
– Document intelligence at the edge
– Video summarization in real time
– Multimodal assistants on local compute
…all become possible without hyperscale dependencies.
🔍 Real-Time RAG (Retrieval-Augmented Generation)
We’re bringing adaptive RAG pipelines directly into the runtime layer:
– Dynamic retrieval strategies (hybrid + dense + filters)
– Integrated memory + agent-based control
– Sub-100ms answer time on local + enterprise datasets
– Optimized for low-latency, high-accuracy enterprise chatbots and copilots
EdgeMatrix is evolving into a complete inference layer – not just for tokens, but for true enterprise intelligence.
The mission: “Make GenAI fast, sovereign, and deployable anywhere – not just on the cloud’s terms.”
Thank you to everyone who followed the Escape the Cloud Tax series.
Let’s build what’s next – together.