Shakti LLM Series – Post 1: Why We Built Sovereign Language Models
After the grand launch of the Shakti LLM Series by Shri Priyank M Kharge, Hon’ble Minister for IT & BT, Government of Karnataka, at the Bengaluru Tech Summit in November 2024, we’ve been on a focused journey to realize a bold ambition:
Make enterprise-grade GenAI sovereign, efficient, and production-ready.
In the months since, the Shakti family has grown rapidly – with the release of six models: Shakti 100M, 250M, 500M, 1B, 2.5B, and 4B – spanning NLP and VLMs, each tuned for real-world use across healthcare, finance, legal, and multilingual customer intelligence.
The Problem: Bloat, Black Boxes, and Bill Shocks
The generative AI wave has largely been defined by billion-parameter behemoths. These models are powerful — but for many enterprises, they come at a steep cost:
1. Cloud-First Giants
- OpenAI, Anthropic, Google: Closed systems with high accuracy, but limited transparency.
- Your data leaves your perimeter.
- Your costs scale uncontrollably.
- Your control is compromised.
2. Open-Source Small Models
- Options like SMoLM, TinyLLaMA, and others are lighter – in theory.
- But most are lab experiments, not production-ready.
- They often lack:
Even great toolchains — like VLLM, LMDeploy, or model quantization frameworks — can’t solve a foundational question:
Can this model run on my infra, with my data, under my policies — and still perform?
Our Purpose: Control. Affordability. Performance.
We didn’t build Shakti for leaderboard headlines. We built it for the trenches — for enterprises, governments, and edge deployments where reliability, ownership, and cost control matter.
With Shakti, you can:
- Own your weights — no vendor lock-in
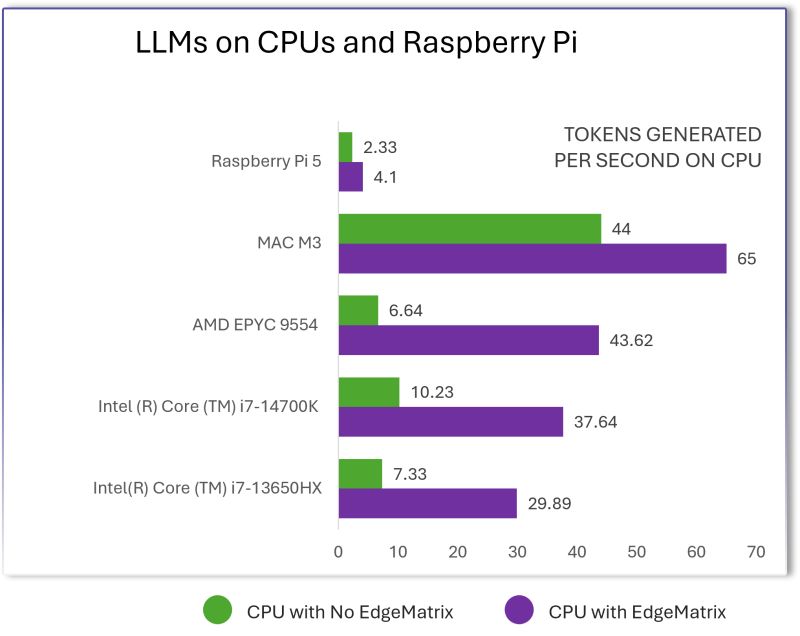
- Deploy at the edge or cloud — even on modest hardware
- Fine-tune on your domain — and trust the output
- Mitigate hallucinations — via in-house HALUMON framework
- Serve diverse populations — with multilingual fluency including Indian languages
- Customize safely — with full lifecycle support
Why Another LLM?
Because none of the available open source models offered this combination of traits we believe are essential:

The Outcome: The Shakti LLM Family
A family of Small Language Models (SLMs) designed for enterprise use, real-time performance, and sovereign deployments:
- 100M – 4B parameter range (8B and 30B are under development)
- Built using VGQA, SwiGLU, RoPE, and DPO
- Benchmarked to outperform models twice their size in reasoning, domain QA, and multilingual understanding
- Optimized for INT8/INT4 quantization — enabling deployment on phones, wearables, drones, and data centers
- Extended with Vision-Language capabilities and ready for OCR, charts, multimodal QA, and more
If you’re building for the real world – where hallucination is not an option, where inference must be fast, and where data must stay sovereign – then Shakti is built for you.
Coming Up in the Series
In Post 2, we’ll unpack Shakti’s internal architecture: how components like Variable Grouped Query Attention (VGQA), RoPE Scaling, and SwiGLU enable speed, accuracy, and efficiency – from 100M up to 4B.
We’ll also cover how we handle long-context tasks, document intelligence, and multi-modal inputs, while keeping latency low – even on edge devices.