Shakti LLMs: Leading the Charge in Mobile AI Innovation
Redefining AI for Mobile Devices
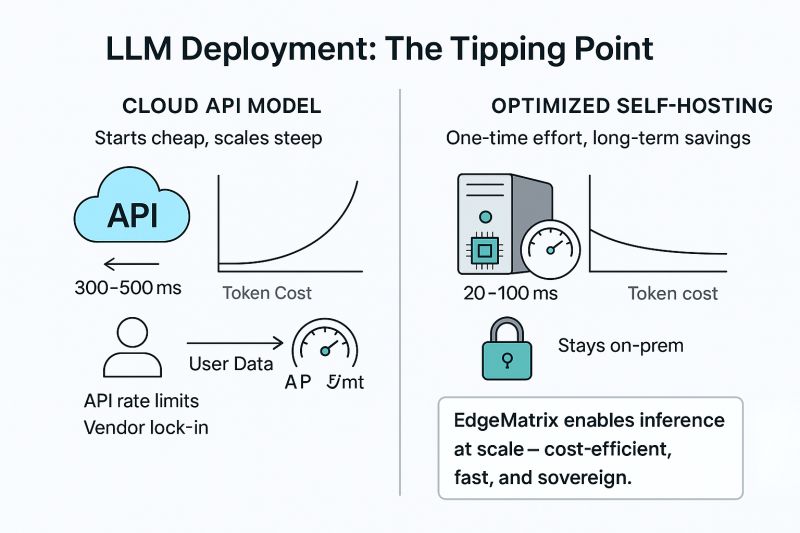
The future of AI is unfolding not just in massive data centers but in the palm of your hand. As mobile devices and edge systems become central to enterprise and consumer technology, the need for efficient, powerful AI solutions has never been more urgent. Shakti LLMs have emerged as a trailblazer in this space, offering high-performance, energy-efficient models optimized for mobile and resource-constrained devices.
In this article, we explore how Shakti LLMs stand out in the competitive landscape, particularly against models like PhoneLM, Gemma, MiniCP, Qwen, and TinyLLaMA, and why they represent the next frontier in mobile AI innovation.
Shakti’s Vision for Mobile AI: A Paradigm Shift
Unlike traditional AI models designed for the cloud, Shakti LLMs are purpose-built for on-device intelligence, addressing critical pain points for mobile AI:
- Energy Efficiency: Shakti’s quantized models significantly reduce power consumption, ensuring sustainable operations even on battery-dependent devices.
- Low-Latency Performance: With token throughput that leads the industry, Shakti enables real-time decision-making on mobile devices, critical for applications like voice assistants, augmented reality, and smart IoT systems.
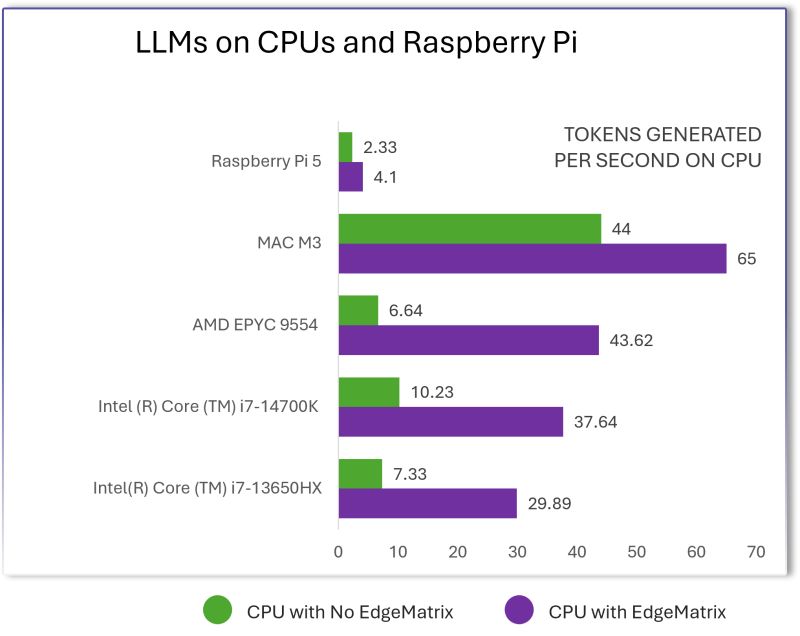
- Hardware Flexibility: Designed to run seamlessly across ARM architectures, Raspberry Pi, and other mobile platforms, Shakti ensures a broad reach across both enterprise and consumer devices.
Beyond Benchmarks: Shakti’s Unique Proposition for Mobile AI
1. Lightweight Architecture, Powerful Outcomes
Shakti’s compact models, such as the 500M and 100M versions, deliver performance that rivals much larger models like PhoneLM, Gemma-2B and MiniCP-2B, but with a fraction of the computational cost.
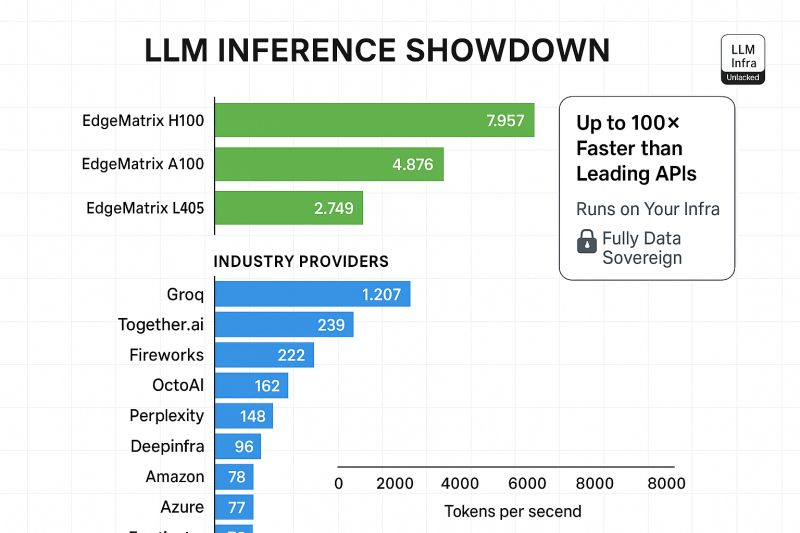
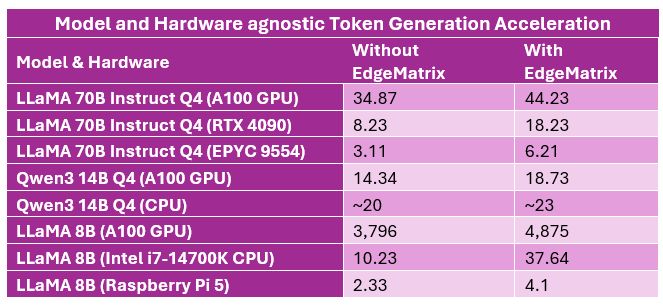
- Example: Shakti-500M achieves 583.88 tokens/sec on GPUs and 48.99 tokens/sec on mobile devices, making it an ideal choice for real-time AI assistants and edge analytics.
2. True On-Device AI: Unlocking New Use Cases
Shakti enables privacy-centric on-device applications, opening doors for industries like:
- Healthcare: Real-time patient monitoring and diagnostics on wearable devices.
- Retail: Personalized recommendations in offline environments, such as kiosks and AR shopping assistants.
- IoT: Smart home systems powered by Shakti’s ultra-compact 100-Q4 model.
3. A Strategic Balance of Performance and Efficiency
While Shakti excels in benchmarks like PIQA (86.2%) and MMLU (71.7%), its true strength lies in balancing computational efficiency and inference power.
- This balance makes Shakti models versatile across mobile platforms and enterprise systems.
The Competitive Landscape: How Shakti Stacks Up
To understand Shakti’s strength, it’s crucial to examine how it fares against competitors like PhoneLM, Gemma-2B, Qwen-1.5B, and TinyLLaMA, which dominate the current mobile AI ecosystem.
Benchmark Highlights
- Reasoning Excellence: Shakti-2.5B leads with 86.2% in PIQA, outclassing Gemma (77.3%) and Qwen (74.2%).
- Factual Knowledge: With 58.2% in TriviaQA, Shakti-2.5B consistently outperforms competitors like Qwen (55.12%) and TinyLLaMA (36.8%).
- Throughput for Mobile Platforms: Shakti-100-Q4 achieves a remarkable 135.87 tokens/sec on mobile devices, significantly ahead of other compact models.
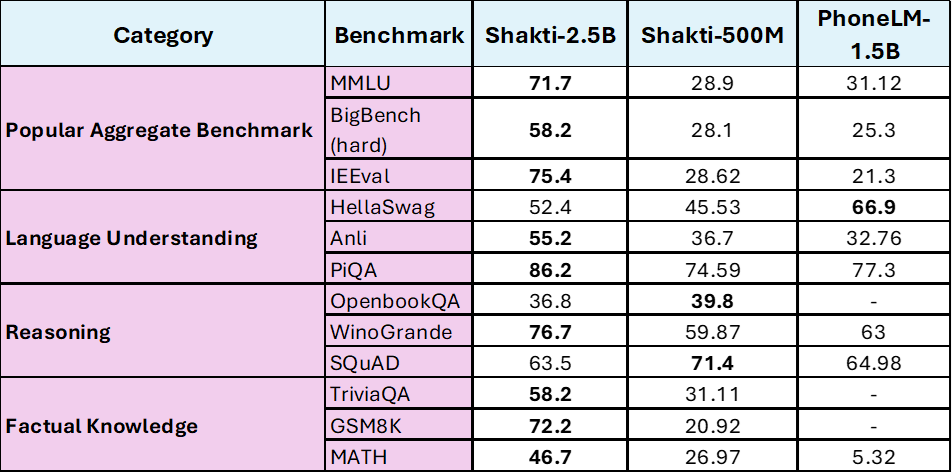
Shakti LLMs vs. PhoneLM: A Comparative Edge for Mobile AI
The competitive landscape for on-device AI models is growing rapidly, with models like PhoneLM, TinyLLaMA, and Gemma vying for dominance in the space of mobile AI solutions. Among these, Shakti LLMs not only match but often exceed the capabilities of their peers, particularly in reasoning tasks, energy efficiency, and scalability for real-world mobile applications.
Key Comparative Insights
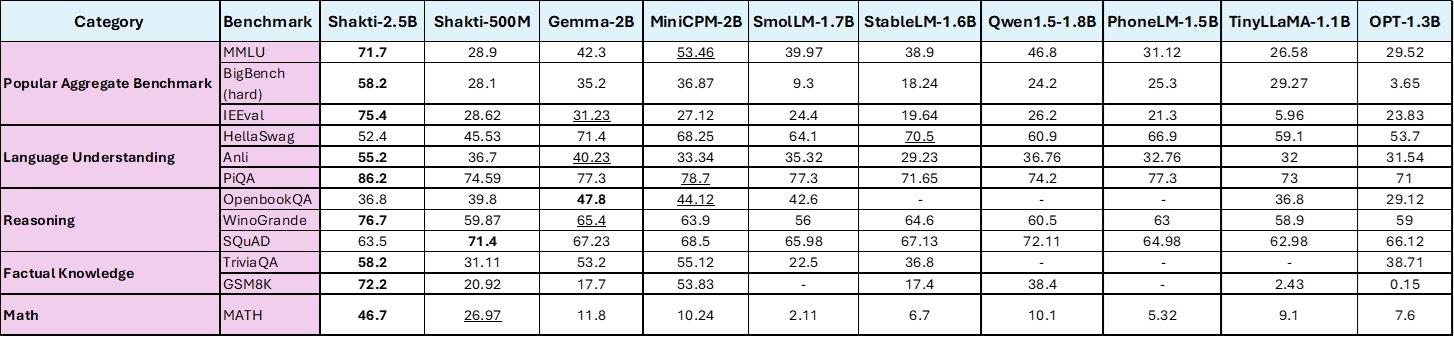
Now, let’s have a closer look at – Shakti LLM 2.5B, 500M and Phone LM
Let’s look at their performance concerning Token per Second on various hardware, like GPU, CPU, Mac, and Mobile (both their Raw models with lower precision – int8 and Quantized Models)
1. Virtual Machine (VM)
a. Processor: AMD EPYC 9554 64-Core Processor
b. Memory: 201 GB RAM
c. Cores – 24
d. GPU: NVIDIA L40s (46 GB)
e. Operating System: Linux-based VM
2. Apple MacBook Pro
a. Processor: Apple M3 Max
b. Memory: 36 GB RAM
c. Operating System: macOS

3. Devices – Raspberry Pi5 and iPhone 14
a. Device: iPhone 14
b. Processor: A15 Bionic
c. Memory: 6 GB RAM
d. Operating System: iOS 18

In my previous article here where I covered on the ShatiLLM’s ability to retain precision as quantized models.
A Timeline of Innovation in SLMs: Contextualizing Shakti’s Position
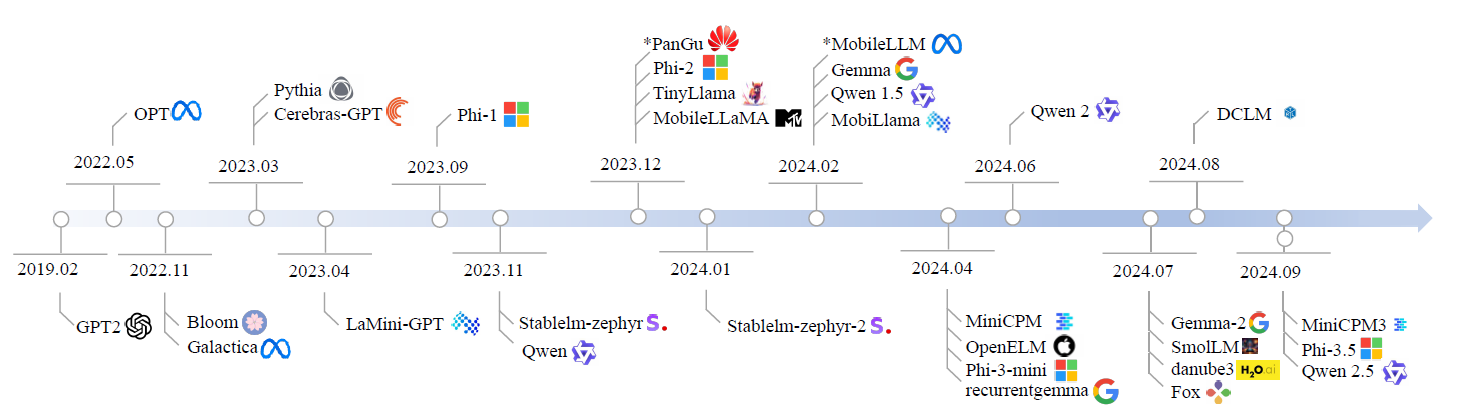
The timeline of Small Language Models (SLMs) reflects the rapid advancements in AI, spotlighting milestones such as TinyLLaMA, Gemma, Qwen, and PhoneLM—models that have set benchmarks for mobile and edge AI optimization. While Shakti LLMs may not yet feature on this timeline, their performance and innovation firmly position them as a formidable contender in this competitive landscape.
This timeline not only serves as an educational overview of the SLM ecosystem but also underscores how these models address key priorities like scalability, efficiency, and edge deployment. Within this evolving ecosystem, Shakti LLMs stand out as a robust alternative, excelling in reasoning capabilities, token throughput, and quantized efficiency, while continuing to evolve in areas like contextual understanding.
By juxtaposing Shakti against the models in the timeline, it becomes evident that it holds its own against established players, particularly in tasks requiring real-time mobile AI performance and privacy-focused on-device applications.
Building on foundational advances in quantization and throughput, Shakti delivers a next-generation solution that aligns with the growing demand for personalized, privacy-centric AI applications on mobile platforms.
Strategic Adoption for Enterprises: A Roadmap
For enterprises looking to leverage Shakti LLMs for mobile AI applications, here’s how to get started:
- Identify High-Impact Use Cases: Focus on areas where real-time decision-making and privacy are critical, such as:
- Begin with Pilot Programs: Deploy Shakti models in small-scale environments to validate their performance and scalability.
- Measure Key Metrics: Track outcomes like latency reduction, throughput improvement, and power savings to quantify ROI.
- Scale Strategically: Expand deployments to enterprise-wide systems, ensuring a balance of performance and resource efficiency across use cases.
As industries continue to demand AI solutions that operate in constrained environments, Shakti LLMs are setting a new standard. By combining high efficiency, benchmark leadership, and real-world applicability, Shakti models empower enterprises to rethink what’s possible with mobile and on-device AI.
With Shakti, the future of AI isn’t just in the cloud—it’s everywhere. Discover how Shakti LLMs can transform your mobile AI strategy. Let’s build a future powered by intelligent, sustainable, and scalable AI solutions.