
At the Core of the Edge: The Energy Performance in Edge AI Chips
“Energy is more problem to AI than compute.” Every AI chip can compute. Few can sustain. As intelligence moves from
0 Comments
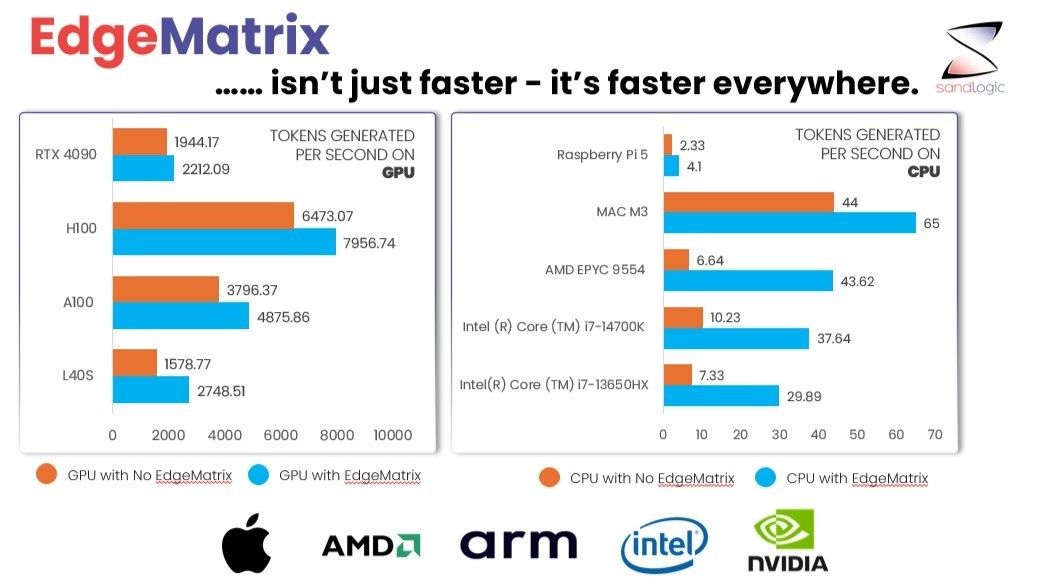
Redefining LLM Inference: How EdgeMatrix Outperforms vLLM and TensorRT-LLM
As Large Language Models (LLMs) continue to evolve, the spotlight is shifting from model accuracy to how efficiently these models

Engineering Scalable Edge AI: The Semiconductor Stack Powering the Future
At SandLogic, we’ve built a complete AI acceleration stack ( silicon, compiler, runtime, and models) all co-engineered to bring high-performance,
Building the Full-Stack AI Future: Chip, Runtime, and Models
For too long, AI hardware and AI research have lived in silos. Hardware vendors chased TOPS and throughput. Model builders