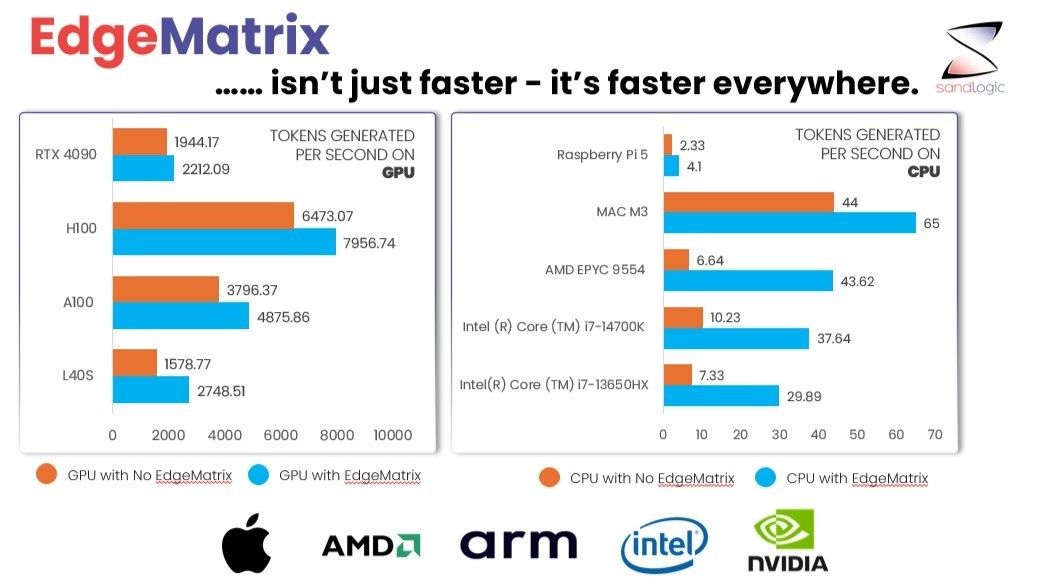
Benchmarking LMCache vs EdgeMatrix: Why Caching Alone Can’t Beat a Smarter Scheduler
In my previous article, “Redefining LLM Inference: How EdgeMatrix Outperforms vLLM and TensorRT-LLM”, I shared benchmark insights comparing leading inference frameworks on throughput and scheduling efficiency.
This time, we went a step further. We added LMCache, a caching extension to vLLM, to see whether advanced caching could close the gap between static optimization and dynamic orchestration. The results were revealing – caching helps, but orchestration wins.
1️⃣ Why LMCache Was Added
LMCache is an extension to LLM serving engines like vLLM, is designed to reduce latency by caching preprocessed context and intermediate results. Theoretically, this should improve Time-to-First-Token (TTFT) and throughput, especially for repeated or overlapping inputs.
But caching, by nature, is reactive – it stores and reuses.
EdgeMatrix, on the other hand, is proactive – it predicts, compiles, and orchestrates.
The benchmark shows the difference clearly, let’s deep dive into our finding across dense and MoE models.
2️⃣ Dense Model Benchmarks
Hardware: NVIDIA A100 (80 GB)

Hardware: NVIDIA L40s

3️⃣ MoE (Mixture-of-Experts) Benchmarks
Hardware: NVIDIA A100 (80 GB)

4️⃣ TTFT: The Latency That Defines User Experience
For real-time AI copilots, assistants, or edge agents, TTFT (Time-to-First-Token) is critical. EdgeMatrix’s scheduler combines preallocation, async prefetching, and kernel fusion, reducing initialization latency before token generation even starts.
In contrast, caching introduces async I/O overheads and indexing steps that can slightly delay first response – especially when workloads vary in structure.
The result:
EdgeMatrix consistently delivers the first token 40-80% faster across all hardware setups.
5️⃣ Caching vs Orchestration: The Architectural Divide

LMCache reuses precomputed data.
EdgeMatrix reuses intelligence. Its CORE (Compiler and Runtime Engine) compiles models into device-specific binaries and dynamically orchestrates them across heterogeneous devices – GPUs, CPUs, and even ARM or Apple Silicon.
6️⃣ Real-World Implications
Caching helps repetitive workloads; scheduling enables concurrent, adaptive ones. That’s where EdgeMatrix shines. Its unified scheduler handles multiple inference requests simultaneously, even at the edge level – laptops, embedded boards, and on-device environments.
This is crucial for agentic AI, where multiple micro-agents invoke language models concurrently for reasoning, planning, and execution. EdgeMatrix intelligently balances those requests, ensuring low latency and predictable responses, even under constrained hardware.
In every test, including LMCache-enabled vLLM, EdgeMatrix consistently outperformed all frameworks – across dense and MoE models, across A100s and L40s. There wasn’t a single scenario where LMCache surpassed EdgeMatrix in TTFT, throughput, or request handling.
While caching accelerates reuse. EdgeMatrix accelerates intelligence.
Insight Snapshot
✅ Up to 80% faster TTFT
✅ Up to 60% higher throughput on dense models
✅ Up to 3× faster on MoE workloads
Caching helps reuse data while EdgeMatrix orchestrates execution itself. That’s why EdgeMatrix isn’t just faster – it’s smarter.
The gap between caching and orchestration mirrors the evolution of AI infrastructure itself – from storage-centric optimization to intelligent execution.
And, as models get larger and more distributed, that gap will only widen in favor of smarter runtimes.