Redefining LLM Inference: How EdgeMatrix Outperforms vLLM and TensorRT-LLM
As Large Language Models (LLMs) continue to evolve, the spotlight is shifting from model accuracy to how efficiently these models can be deployed. As models grow in complexity, the ability to deliver low-latency, high-throughput inference has become the critical factor determining real-world deployability for enterprise AI.
At SandLogic, we’ve built EdgeMatrix – EdgeFlow, our AI acceleration framework designed to optimize inference across GPUs, CPUs, and edge devices. In our latest benchmarks, we compared EdgeMatrix (v0.0.4) against two widely-used inference frameworks like vLLM (v0.10.2) and TensorRT-LLM (v1.0.0) – across both dense models (like Llama and Qwen) and Mixture-of-Experts (MoE) architectures (like Qwen-MoE, DeepSeek-MoE, and Phi-Mini-MoE).
The results were striking!!!
1. The Benchmark Setup
All tests were conducted using NVIDIA A100 (80 GB) and L40s GPUs under FP16 precision, with 1024-token prefill windows and identical environment configurations. We used the following models:
- Dense Models: Llama-3.2-3B, Qwen-3B, Qwen-4B
- MoE Models: Qwen1.5-MoE-A2.7B-Chat, DeepSeek-MoE-16B-Chat, Phi-Mini-MoE-Instruct
For each test, we measured tokens per second (throughput) under equivalent hardware utilization and parallel request loads.
2. The Results
Benchmark Summary
All benchmarks were conducted using identical environments on NVIDIA A100 (80 GB) and L40s GPUs, with FP16 precision and a 1024-token prefill window. The following models were used for testing:
- Dense Models: Llama-3.2-3B, Qwen-3B, Qwen-4B
- MoE Models: Qwen1.5-MoE-A2.7B-Chat, DeepSeek-MoE-16B-Chat, Phi-Mini-MoE-Instruct
Dense Model Throughput (tokens/sec)
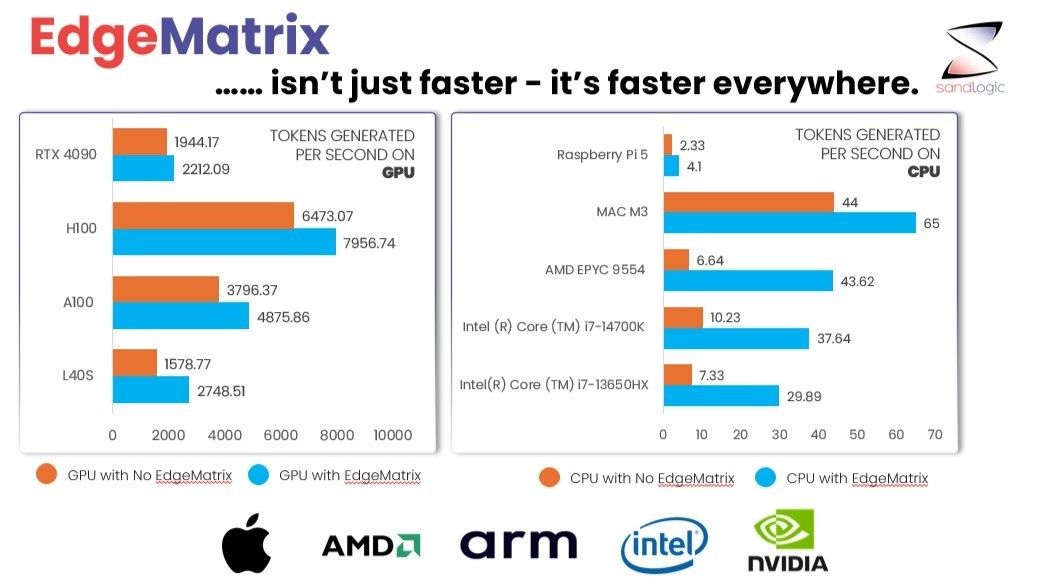
Across both GPUs, EdgeMatrix consistently outperformed vLLM and TensorRT-LLM by 10–30%, using the exact same model checkpoints and configurations.

Mixture-of-Experts (MoE) Model Throughput (tokens/sec)
EdgeMatrix’s advantage widens dramatically with MoE architectures, where it achieves up to 96 % higher throughput thanks to optimized expert routing, fused-expert execution, and balanced scheduling.

3. Why EdgeMatrix Performs Better
a. Unified Scheduler and Runtime
Unlike TensorRT-LLM, which is tightly coupled to NVIDIA GPUs, vLLM offers partial CPU and ARM support, but its optimizations and scheduling capabilities are primarily tuned for GPU inference.
EdgeMatrix, on the other hand, is designed from the ground up for heterogeneous environments; it is capable of orchestrating multiple concurrent requests seamlessly across GPUs, CPUs, ARM devices, and even laptops or on-edge systems.
Below is the screenshot where one can see EdgeMatrix serving multiple parallel requests, setup details here
- Model : Llama-3.2-3B Quantized (int4)
- CPU: Intel i7 10870H
- RAM: 16GB

b. Intelligent Workload Orchestration
EdgeMatrix’s EdgeFlow engine dynamically distributes workloads between compute backends (GPU, CPU, or edge accelerators) using a hybrid scheduling algorithm that minimizes idle cycles and token latency. Unlike traditional in-flight batching, EdgeMatrix continuously re-balances workloads to maximize real-time token throughput which is a critical advantage for multi-session environments.
c. CORE: Compiler and Runtime Engine
At the heart of EdgeMatrix lies CORE – the Compiler and Runtime Engine which performs on-the-fly graph optimization, kernel fusion, and device-specific optimization. CORE automatically compiles models into optimized binaries tailored for the target hardware, whether NVIDIA, AMD, Intel, ARM, or Apple Silicon, and manages the runtime execution environment for consistent, deterministic performance.
By abstracting hardware dependencies, CORE ensures that models can run seamlessly across heterogeneous devices – from cloud GPUs to edge systems and even personal laptops without requiring any manual reconfiguration or code changes.
d. Native MoE Optimizations
EdgeMatrix’s architecture natively supports fused-expert execution and parallel expert routing for Mixture-of-Experts models, enabling concurrent expert activation without CPU bottlenecks. This results in significant throughput gains – up to 96 % higher than baseline runtimes on MoE benchmarks.
4. Ecosystem Comparison
While both vLLM and TensorRT-LLM offer efficient schedulers. EdgeMatrix stands apart by combining performance leadership with cross-platform deployment which is crucial for enterprises standardizing on hybrid and edge architectures.

5. What This Means for the Industry
The industry is converging on smarter scheduling but diverging on deployment breadth. As models grow larger and more modular (e.g., MoE architectures), frameworks that can maintain consistent throughput across varied hardware will define the next phase of AI scalability.
EdgeMatrix shows that real-time inference doesn’t have to be GPU-exclusive — and that optimized orchestration can yield double-digit performance improvements even on identical silicon.
6. The Road Ahead
We’re extending EdgeMatrix to:
- Support multi-modal inference acceleration (text + image + audio)
- Integrate adaptive quantization for mixed-precision deployments
- Introduce EdgeFlow-X, a scheduler variant optimized for concurrent multimodal pipelines
These advancements will continue to strengthen EdgeMatrix as a platform that truly “adds intelligence to inference.”
Inference is becoming the new frontier of innovation. EdgeMatrix isn’t just about faster token generation, it’s about enabling enterprises to deploy AI anywhere, efficiently and affordably.