At the Core of the Edge: The Energy Performance in Edge AI Chips
“Energy is more problem to AI than compute.” Every AI chip can compute. Few can sustain. As intelligence moves from cloud to edge, power budgets shrink, and thermal envelopes tighten. The real innovation today isn’t faster math – it’s smarter energy.
1. The Redefinition of “Performance” in AI Compute
In the early phase of AI acceleration, performance was defined by raw compute throughput measured in FLOPS, TOPS, or inference latency. For data centers with abundant cooling and power infrastructure, this definition worked. But as AI workloads migrate toward edge environments like drones, wearables, autonomous vehicles, and IoT devices, the definition has become obsolete.
The emerging metric of interest is energy performance, expressed as TOPS per Watt (TOPS/W) and, more holistically, Energy Per Inference (EPI) – the total energy required to perform one inference. While TOPS/W indicates how efficiently computation is executed, EPI exposes the real-world energy footprint, including data transfers, cache operations, and activation computations.
This shift marks a fundamental evolution in design philosophy: a high-performing edge AI chip must not just compute faster, but compute smarter – maximizing inference/ tokens per joule.

2. The Energy Bottleneck in Modern AI Systems
In modern neural systems, computation isn’t the main consumer of power – data movement is.
Fetching a single word from DRAM can consume 100×–1000× more energy than performing a single MAC (Multiply-Accumulate) operation. Thus, the real bottleneck lies in communication between compute units and memory hierarchies.
Architects have begun rethinking this imbalance through:
- Spatial Dataflow Architectures – Mapping neural graph operations across a systolic or mesh-based fabric to reuse activations and weights locally.
- Hierarchical Memory Design – Layered SRAM and eDRAM caches to reduce DRAM access.
- Precision Adaptivity – Dynamically adjusting precision (FP16, INT8, INT4) to match the energy profile of each inference stage.
These principles ensure that each bit of energy spent contributes meaningfully to inference – aligning data locality with compute intensity.
3. From Cloud to Edge: Energy-Performance Tradeoffs
While GPUs and TPUs deliver massive throughput, their energy efficiency (1-2 TOPS/W) is bound by thermal and power constraints. Edge AI processors, by contrast, operate in sub-watt envelopes and emphasize localized inference under tight latency constraints.
A more holistic measure here is Energy-Delay Product (EDP) – the product of energy consumption and execution time. Minimizing EDP ensures both low power and low latency, achieved through fine-grained control of compute pipelines, voltage domains, and memory access paths.
The design objective is no longer maximizing compute density but minimizing total energy per inference.
4. Architecting for Sustainable Intelligence
4.1 Dataflow and Parallelism
Modern AI accelerators decouple data and control flow, mapping neural operations spatially to minimize idle cycles. This dataflow parallelism optimizes both latency and power by ensuring every compute unit performs useful work.
4.2 DVFS and Clock Gating
Dynamic Voltage and Frequency Scaling (DVFS) dynamically adjusts power rails to match workload demand. Coupled with fine-grained clock gating, this yields up to 40% dynamic power savings without affecting inference accuracy.
4.3 Compiler-Aware Energy Optimization
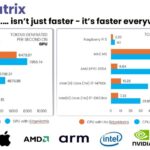
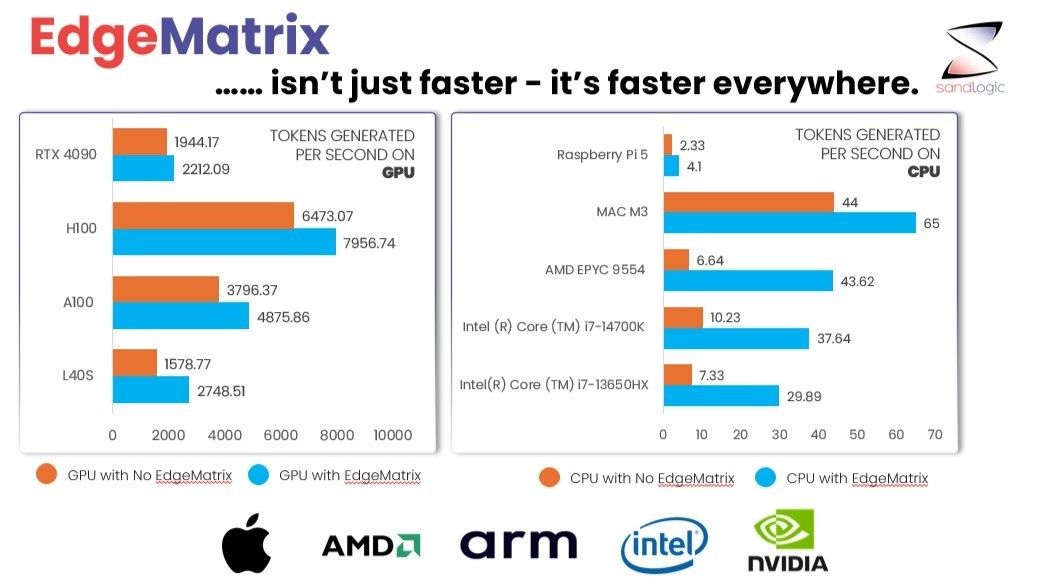
Software plays a pivotal role in hardware energy efficiency. SandLogic’s EdgeMatrix CORE compiler-runtime framework co-optimizes models for energy: fusing layers, minimizing tensor movement, and allocating compute dynamically across CPU, GPU, and NPU clusters – achieving up to 5× CPU and 74% GPU inference acceleration without architectural changes.
5. The ExSLerate Paradigm: Rethinking Energy at the Core
SandLogic’s ExSLerate AI Co-Processor embodies a shift from compute-centric to energy-centric design. Delivering 22 TOPS under 2W, it achieves one of the highest TOPS/W ratios in its class, but its true innovation lies deeper: in how it reduces EPI.
While most accelerators focus on lowering computation energy, ExSLerate V2 targets the dominant energy cost, data movement. Its architecture minimizes unnecessary memory fetches, compresses data in-flight, and performs all activations on-chip.
5.1 Zero Refetch of Data
ExSLerate V2 introduces a patented data flow mechanism that ensures weight data is not fetched twice from the memory even when the weight data exceeds the local buffer size.
5.2 Dynamic Sparsity
By identifying zeros and low-significance data on-the-fly, ExSLerate dynamically compresses tensors during runtime, ensuring that no zero is stored in the memory.
5.3 KV Compression By dynamically adjusting the precision and compressing the KV cache data ExSLerate DMAs reduce the effective size of KV cache by 50% in models like Llama 8B when compared to raw INT8.
5.3 All-Purpose Activation Engine
Traditional accelerators offload non-linear activations (GELU, SiLU, tanh) to CPUs, causing significant latency and power drain. ExSLerate integrates a custom Taylor-Series Engine that computes all activations directly on-chip, using BF16 intermediate precision for numerical fidelity. Accuracy drop across activations: <0.12% (avg). Result: zero CPU offload and a fully self-contained compute pipeline.
5.4 Lossless INT8→INT8 Compression
ExSLerate’s DMA subsystem introduces bit-plane mapping based lossless INT8 compression, shrinking DDR data size by 28–30% while maintaining numerical precision, strictly INT8 → INT8, not quantization.

This compression not only reduces DDR energy but also increases throughput by keeping compute cores consistently fed with data.
6. Quantifying the Impact: EPI vs. TOPS/W
The true innovation of ExSLerate V2 lies in its 30–40% reduction in Energy Per Inference (EPI). While competitors optimize computation energy (TOPS/W), ExSLerate targets total energy, incorporating weight movement, KV cache, and activation energy.
For example in figure 2, in LLaMA 7B inference, data movement dominates total energy (up to 85% at low batch sizes). ExSLerate’s architecture reduces this dramatically across batch scales, achieving consistent EPI gains:

7. Intelligent Energy Scaling: Toward Neuromorphic Efficiency
The next leap in AI silicon will be adaptive energy intelligence, where the chip continuously senses workload intensity and dynamically scales its voltage, frequency, and active cores. By combining architectural techniques like sparsity and compression with software-defined energy profiling, SandLogic envisions a future of autonomous power scaling.
Future ExSLerate generations aim for neuromorphic energy behavior, consuming power only when neurons (compute units) fire, mimicking biological systems in silicon.
Conclusion
Energy performance is the true core of the edge revolution – defining scalability, sustainability, and real-world AI viability.
While most accelerators chase higher TOPS/W, ExSLerate redefines efficiency through Energy per Inference (EPI), cutting total inference energy by 30-40% across models and batch sizes.
This isn’t just engineering progress; it’s a design philosophy where architectural intelligence drives computational efficiency. As AI shifts from cloud to edge, ExSLerate proves that true intelligence isn’t about power – it’s about how little energy it needs to perform.